







When I first started using PyTorch, I was not happy with this new data loading paradigm that I had to learn. I was migrating to PyTorch from Keras, which wasn't as prescriptive. PyTorch had a specific way it wanted to access data, and I didn't know what it was, nor did I really want to spend time learning yet another way to load data into a deep learning framework.
But I didn't really have any choice, so I got to work.
I ended up looking through the code for the MNIST dataset to figure out what I needed to do. Fortunately, what I needed to do was much simpler than what the MNIST set does. These prepackaged datasets in PyTorch (they're packaged in the TorchVision project, you should check them out if you haven't yet) are very handy in the initial phases of putting together a model, especially since PyTorch uses a channel instead of a pixel abstraction. You don't need to worry about dimensionality as much in PyTorch, so if you define an architecture that works with one dataset, it can be tuned to another set very easily. These prepackaged datasets, like the MNIST set, will download the data from the internet for you, and then handle all access to the data in the downloaded repositories. Very nice, and surprisingly simple, but still more work than I needed to go through.
The data that I'm handling has been archived in HDF5. All I needed to do was provide access to the data via the appropriate PyTorch datatype, which was this easy:
That's it! A couple of things to note: transforms, the close(.) method, and the built-in methods are what you need to support.
So, first, transforms are a way to change the nature of the data you process. They're in the torchvision.transforms module, and the stock transforms support either tensor or PIL image datatypes. If you're going to use stock transforms, you'll want to convert your data into tensors when you load them into the dataset. Otherwise, it really doesn't matter. This can be handy for changing the dimensionality of loaded data dynamically.
The close(.) method...well, you probably don't need that. I do because I have an HDF5 data backend, and HDF5 datasets use file open/close semantics.
Finally, built-ins. So, we have two that a dataset must support: __getitem__(.) and __len__(.). These allow data loaders to access your dataset pythonically — using array-style indexing (e.g. dataset[index] returns a datum) and supporting the len(.) builtin function.
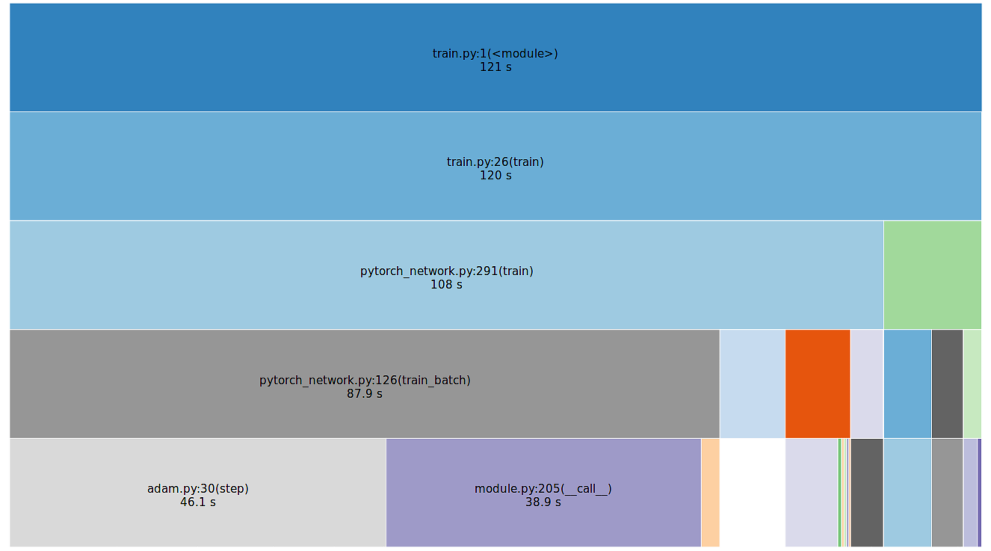
That's really it. The Dataset/Dataloader pattern separates concerns nicely, and is surprisingly easy to migrate into.



No comments:
Post a Comment